使用ChilloutMix生成漂亮美少女

ChilloutMix
关于ChilloutMix
ChilloutMix是一款极具创意和实用性的设计工具,它擅长绘制逼真的插图和人物形象。ChilloutMix的特色在于它可以创造出非常逼真的效果,使得插图和人物形象看起来犹如真实照片一样。这种逼真的效果,让人们可以在视觉上更加直观地感受到插图和人物形象所要表达的信息和情感。
ChilloutMix的使用非常方便,它提供了丰富的插图和人物形象库,用户可以轻松地找到自己所需的素材,然后通过ChilloutMix的工具进行编辑和调整。不仅如此,ChilloutMix还提供了各种特效和滤镜,让用户可以进一步优化和调整插图和人物形象的效果,使得其更加个性化和独特。

ChilloutMix
如何使用ChilloutMix
首先我们要准备好stable diffusion webui,如果有条件的朋友可以直接去google的Colab一键运行,这里给一个一键运行的地址:
https://colab.research.google.com/drive/1vhsF89FWUww-XhLa1MYXnLeqvmEiO1Yr?usp=sharing
如果访问不了google的朋友,可以使用一键安装包:
https://pan.baidu.com/s/17rVcEJWRl5-52CneRgXNQg?pwd=aisd
下载后,解压,直接运行

运行启动助手

点击“自动运行”

weui
这里有很多的参数,我们只要注意以下几种:
- 模型:已经自动选择了chilloutmix
- 文生图:也是自动选择了
- 提示词:可以输入任何单词和命令
- 反向提示词:不希望图里出现的单词和命令
- 采样方法:不同的方法生成效果不同
- Sampling steps:采样步数,一般在20-30比较好
- 宽度和高度:生成图片的大小
- 提示词相关性CFG:数字越大与提示词等越相关
- 随机种子:随机数
好了,我们可以尝试这样的一个组合:
模型:Chilloutmix-Ni-pruned-fp32-fix 提示词:head portrait, realistic, 1girl, eyes, loli, lots of frills, black long dress, starry sky, black hair blowing in the wind, trees, bloom light effect 反向提示词:(low quality, worst quality, trembling, cropped face:1.4), cap, leg, (hand:1.6), nsfw 采样方法:Euler a Sampling steps:20 宽度和高度:1200×800 提示词相关性CFG:7.5 随机种子925943797
- 点击右边的“生成”,可以得到这样画面

生成效果
- 让我再试试另一种复杂一点的:


#AI绘画#最近AI画画好像特别火,看到别人用AI制作了好多好看的图片,我也手痒去找了教程试试,没想到还挺好用。以下是我个人总结的经验分享,希望可以帮到各位。
一、安装 Python 环境
Python下载地址:
https://www.python.org/downloads/release/python-3108/
安装的时候最好是把自动添加环境变量选上,不然自己添加太麻烦了。 然后需要安装Git。Python安装这个网上大把教程,不细说了,接下来进入正题。
二、安装UI绘画环境
安装 stable-diffusion 的 UI,地址:
https://github.com/AUTOMATIC1111/stable-diffusion-webui
安装好后,还需要安装一些额外的文件和模型。这里用到的是目前比较火的两个模型chilloutmix 和 Lora。当然也可以自己再Github、Gitee和Civitai上去找自己满意的。
1、sd-v1-4.ckpt
下载地址:https://huggingface.co/CompVis/stable-diffusion-v-1-4-original/resolve/main/sd-v1-4.ckpt
2、chilloutmix模型
下载地址:https://civitai.com/models/6424/chilloutmix
3、Korean-doll模型
下载地址: https://civitai.com/models/7448/korean-doll-likeness
4、GFPGANv1.4.pth 脸部优化
下载地址:https://github.com/TencentARC/GFPGAN/releases/tag/v1.3.8
把1 和 2 下载后放在 models/Stable-diffusion 目录,3 下载后放到 models/Lora 目录,最后一个解压后放在项目的根目录。
 启动项目
启动项目
上述几点全部准备好后,即可启动项目了。Windows系统用webui.bat启动,其它系统用webui.sh(应该是,没用过)
PS:如果Github访问速度过慢,可能会出现超时的情况,可以使用FastGithub工具:
地址:https://github.com/dotnetcore/FastGithub
三、运行项目
一切加载完毕后,即可开始使用了。
在浏览器中输入127.0.0.1:7860,即可访问AI图片页面了。
 AI图片页面
AI图片页面
然后我们去到上面说到的网站https://civitai.com/,随便找个二次元美少女,点进去找到右下角,复制数据。
 随便找个美少女图片
随便找个美少女图片
然后点击这个斜箭头按钮,就会自动填充参数,然后点击生成就可以了,生成的时间跟训练模型有关,有的会很快,有的需要非常久。
 参数是自动填充的
参数是自动填充的
然后就可以得到AI生成的图啦~
AI绘画之训练自己的Lora模型播报文章
我爱AI2023-03-03 16:23山东
关注
一、Lora简介**
二、Lora一键包安装教程
三、Lora使用教程
四、常见错误除
一、Lora简介**
LoRA: Low-Rank Adaptation of Large Language Models 是微软研究员引入的一项新技术,主要用于处理大模型微调的问题。目前超过数十亿以上参数的具有强能力的大模型 (例如 GPT-3) 通常在为了适应其下游任务的微调中会呈现出巨大开销。 LoRA 建议冻结预训练模型的权重并在每个 Transformer 块中注入可训练层 (秩-分解矩阵)。因为不需要为大多数模型权重计算梯度,所以大大减少了需要训练参数的数量并且降低了 GPU 的内存要求。
Stable Diffusion 的全模型微调过去既缓慢又困难,这也是 Dreambooth 或 Textual Inversion 等轻量级方法变得如此流行的部分原因。使用 LoRA,在自定义数据集上微调模型要容易得多。
详细的原理分析见右侧链接:https://www.cnblogs.com/huggingface/p/17108402.html
简单来说,lora模型为我们提供了更便捷更自由的微调模型,能够使我们在底膜的基础上,进一步指定整体风格、指定人脸等等,而且lora模型非常的小,大部分都只有几十MB,非常的方便!
二、Lora一键包安装教程
秋叶大佬已经发布了一个本地Lora一键包,比较的方便,可以参考下方视频安装使用,本文是文字版教程。
注意本文默认是使用的N卡,A卡的道友暂时好像不能使用,会非常的慢
秋叶lora视频教程链接:https://www.bilibili.com/video/BV1fs4y1x7p2/?spm_id_from=333.999.0.0
一键包下载链接:https://pan.quark.cn/s/d81b8754a484
百度网盘链接:[url=链接:https://pan.baidu.com/s/1RmXoUar52KFJ4DdQU_UoWQ?pwd=r50l]链接:https://pan.baidu.com/s/1RmXoUar52KFJ4DdQU_UoWQ?pwd=r50l[/url]
下载完一键包之后,先安装包里的两个软件
其中python版本必须是python3.1,即使本地有python,还是建议再安装一个3.1版本。
安装python的时候记得勾选将python加入环境变量,如下图红框

安装完两个软件后,将鼠标移动到电脑左下角开始图标,选择“windows powershell”
输入命令:Set-ExecutionPolicy -ExecutionPolicy RemoteSigned
遇到询问输入 y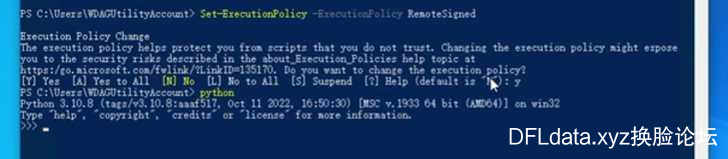
同时可以在这里验证python是否安装成功,输入python将显示出python版本为3.1.
现在进入lora-scripts文件夹,先双击运行“强制更新.bat”文件
如果报错提示没有git或者不识别git命令,说明你的电脑没有git,需要下载安装一个,
git下载链接:https://git-scm.com/download/win
安装完git再重新运行“强制更新.bat”文件
更新完毕后,右键:“install-cn.ps1”文件,选择“使用powershell运行”。
注意,这里有一个非常常见的错误就是提示“ 其他依赖安装失败! ”如下图
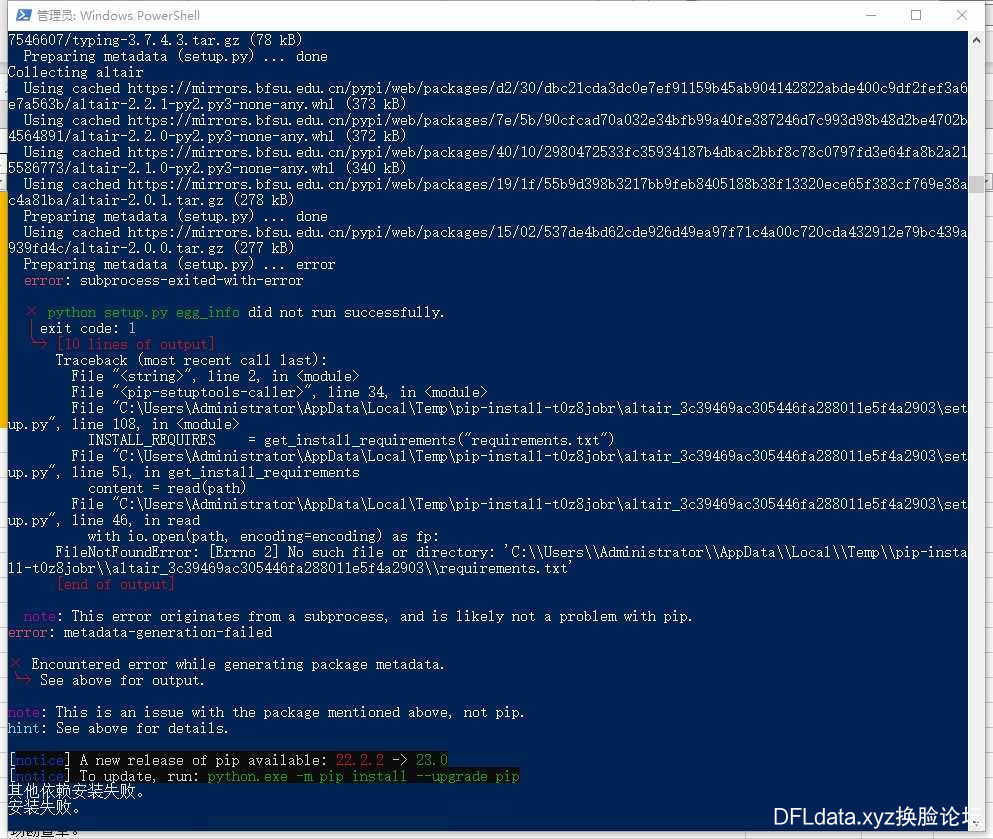
遇到这个错误,重新运行“强制更新.bat”文件
然后再运行“install-cn.ps1”文件。
“install-cn.ps1”文件正常运行最后会提示“安装完毕”,如下图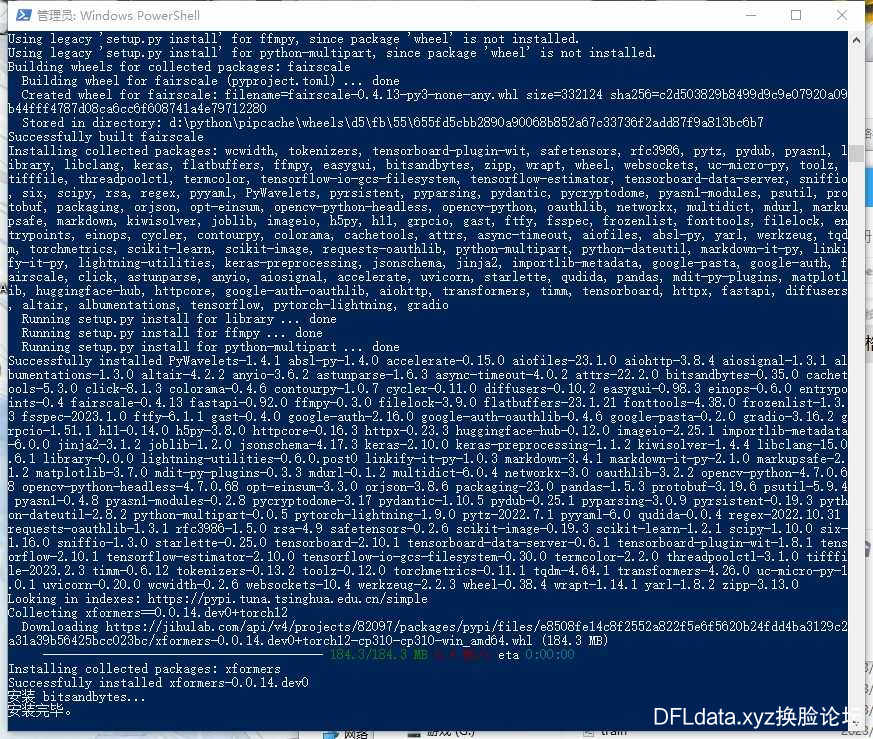
然后现在就进入了素材准备的阶段,首先自己准备10-100张图片,40张左右效果就差不多。
将所以的素材图片放到同一个文件夹,然后进入SDwebUI界面,选择“ 训练 ”标签,点击图像预处理
在源文件输入素材文件夹位置,并填上输出文件夹位置,勾选下方第三个自动焦点裁切和最后一个deepbooru打tag的选项
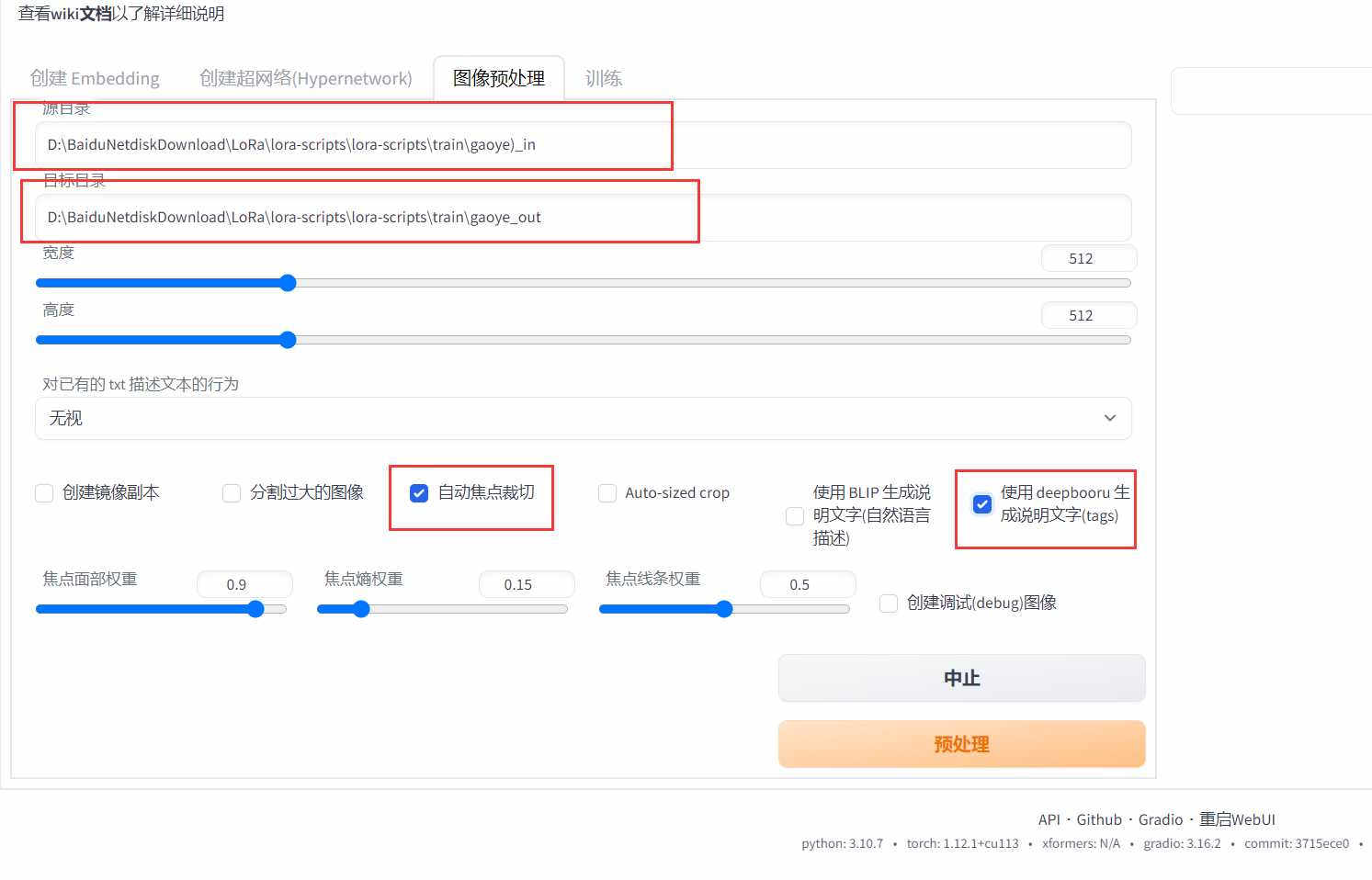
点击预处理,会在设置的输出文件夹中生成裁剪后的图片以及图片相应tag的txt文件
这里如果显卡大小小于8G的话,建议裁剪成512512大小的图片,512640最少需要8G显存
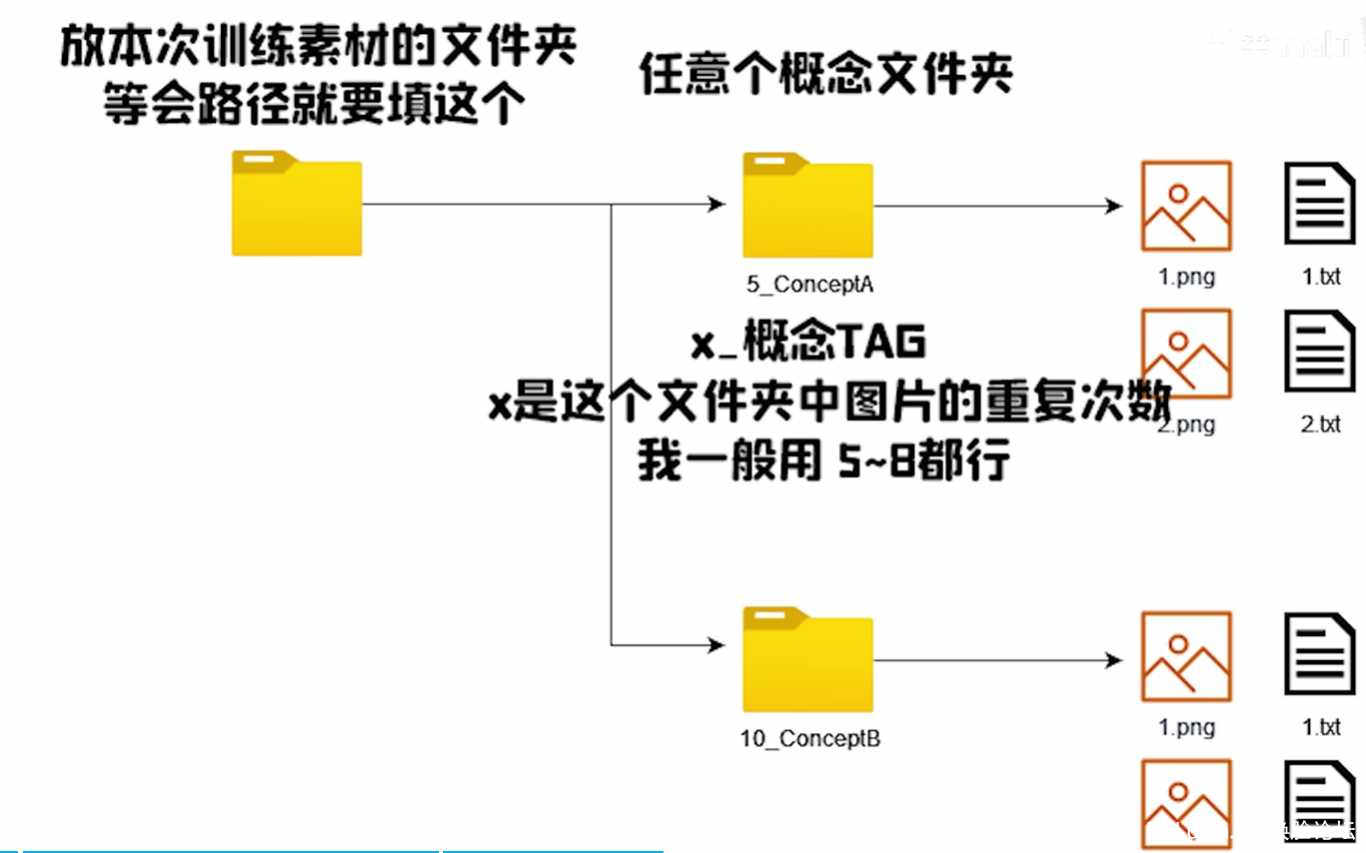
得到素材文件后,,在lora-scripts文件夹下新建一个train文件夹,然后再下方再创建一个文件夹,命名随意,但是需要记住。比如我创建了就是sucai文件夹。
在这个文件夹下再创建一个文件夹,这个文件夹有严格的命名格式。
要求为:数字_名称,如6_sucai。
数字代表的是这个文件夹下的素材使用几次,显存大的道友可以设置多个,一个的话也可以。
如果素材文件比较少的情况下,可以设置6,如果100张图以上可以设置为2或者3,甚至1也行,不然可能会炸
全选复制裁剪后的图片以及所以的txt文件到上面刚创建的文件夹下。比如我这就是..trainsucai6_sucai\
现在素材准备好了,我们修改一下“ train.ps1 ”文件,右键使用文本编辑器打开
我们需要修改的参数如下图所示:

其中$pretrained_model ,不是指的SDwebUI左上角的模型路径,而是这次训练lora模型主要参考的模型。
存放位置一般为..lora-scriptssd-models\
这里我们需要去准备一个模型放在这个路径中,推荐直接复制SD中的主模型过来改个名字。
注意,经过群友大量测试,推荐使用SD1.5模型作为lora丹底。
下载链接:https://huggingface.co/runwayml/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.ckpt
将新下载的SD1.5,如果之前下过就到从..stable-diffusion-webuimodelsStable-diffusion中找
复制到..lora-scriptssd-models路径中
最好重命名一下,比如我就是重命名为model.ckpt
然后就填入配置文件
$pretrained_model = "./sd-models/model.ckpt"
注意:有的道友选的丹底是SafeTensor格式的,那就改成
$pretrained_model = "./sd-models/model.s afetensor "
**
$train_data_dir**指的就是我们刚才创建的存放素材的位置,我这里就填入
$train_data_dir = "./train/sucai/"
不需要填入带数字的文件夹。
下方的训练相关参数,$resolution指的是图片分辨率。
显存小于8个G的道友就老老实实训练512,512,不然显存直接爆炸
$max_train_epoches指的是训练的epoch数,建议数值10-20,但一般15就差不多了。数字越大训练时间越久。
其他几个参数小白的话可以不用动,默认就可以了。学习率这里也不用动
等能够熟练操作之后,可以自己调整参数以便得到更好的效果。
再往下,输出设置这里
可以通过修改$output_name后方的值修改输出的lora模型文件名,建议输入英文名,不要用中文,比如我设置为 gaoye 。
lora文件类型建议设置$save_model_as为safetensors
改完参数后,一定记得保存文件。然后关掉文件,“ train.ps1 ”文件,选择“使用powershell运行”。
如果显存没爆炸,且上述参数都设置的情况下,正常就开始进入训练界面了。
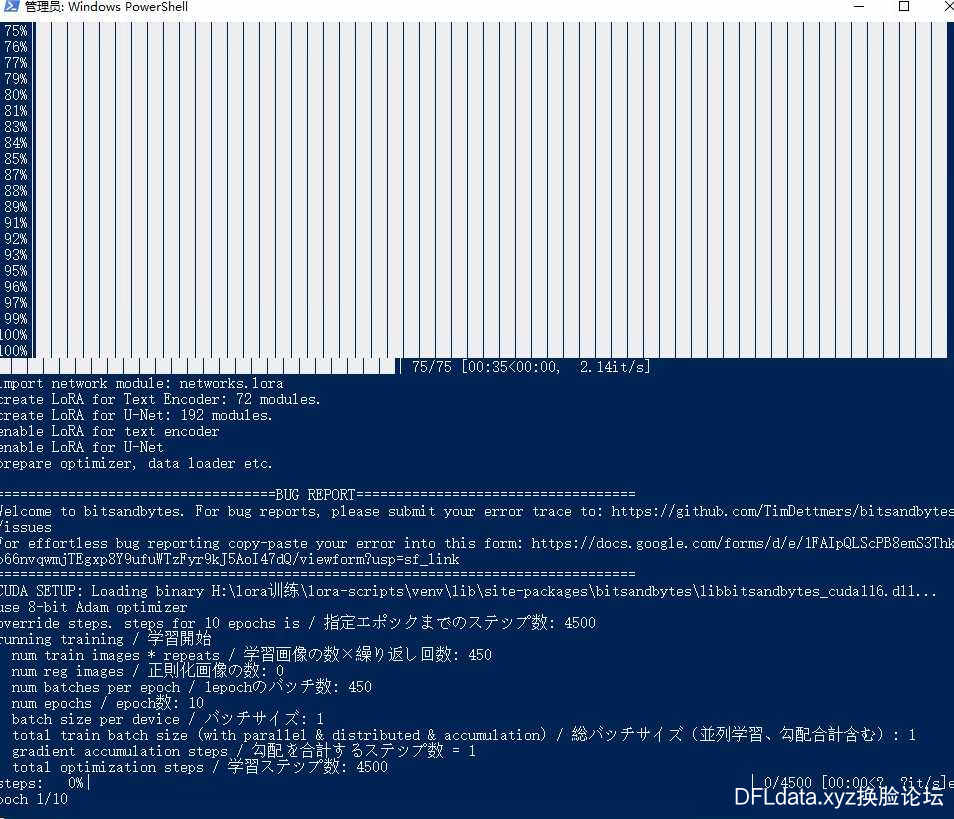
出现epoch轮数的时候,就证明你已经正常进入训练过程了!
根据设置的参数已经你显卡的性能,训练的时间不等。
等待训练完毕,打开..lora-scriptsoutput文件夹,复制生成的gaoye.safetensors复制到sd中的 *..stable-diffusion-webuimodelsLora* 路径中
其他几个带数字的文件为中间文件,可以丢弃。
至此,我们自己的lora模型已经训练完成,可以进行使用了!!
三、Lora使用教程
这部分不再赘述,可以参考入门教程的第七部分
入门教程:https://dfldata.xyz/forum.php?mod=viewthread&tid=12756&page=1#pid390482
四、常见错误排除
1.运行“install-cn.ps1”文件,提示“其他依赖安装失败!”如下图
答:遇到这个错误,重新运行“强制更新.bat”文件,然后再运行“install-cn.ps1”文件。
2.运行“强制更新.bat”文件,报错提示没有git或者不识别git命令。
答:说明你的电脑没有git,需要下载安装一个,
git下载链接:https://git-scm.com/download/win
安装完git再重新运行“强制更新.bat”文件
3.运行“train.ps1”文件提示“CUDA out of memery”错误。
答:显存不够了,调小参数设置的分辨率,支持非正方形,但必须是 64 倍数。
同时可以加大虚拟内存,具体方法百度。
实在机器性能有限,可以使用在线的网站训练lora模型。
参考链接:https://www.bilibili.com/read/cv21450198
4.运行“install-cn.ps1”文件创建虚拟环境失败
答:检查python版本,以及电脑装过anaconda,需要先关掉conda自动激活base环境,方法自行百度。不然运行脚本时环境会冲突。
5.运行的“train.ps1”文件的时候,提示Error no kernel image is available for execution on the device。
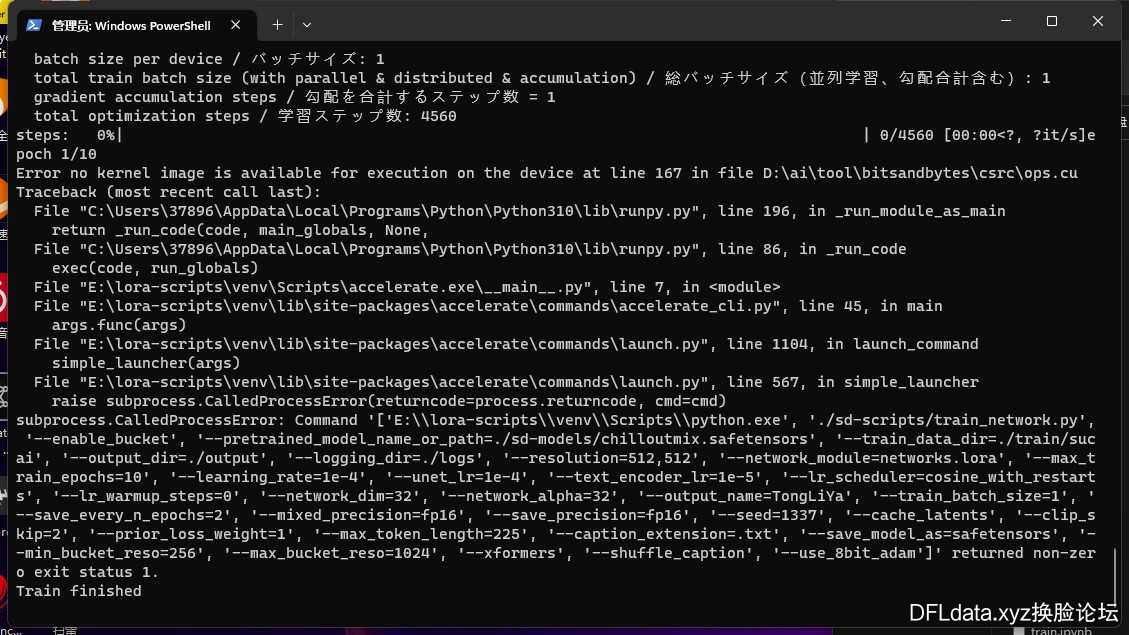
答:删掉 “train.ps1” 文件中,下方红框中的命令,保存后重新运行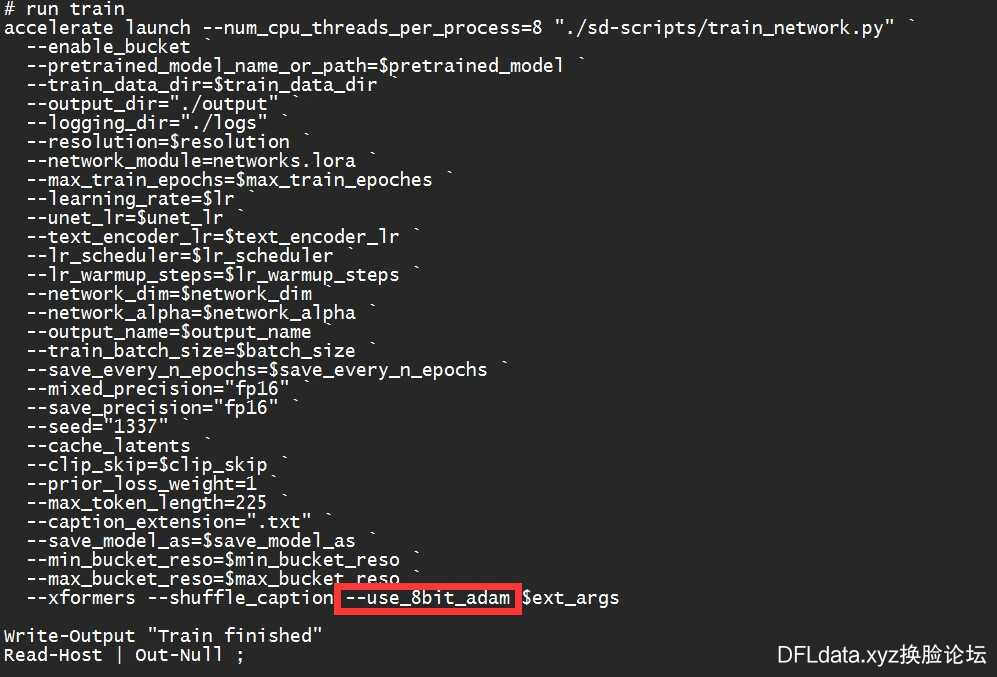

问题一:Stable Diffusion是什么
Stable Diffusion是一个文本到图像的潜在扩散模型,由CompVis、Stability AI和LAION的研究人员和工程师创建。它使用来自LAION-5B数据库子集的512x512图像进行训练。使用这个模型,可以生成包括人脸在内的任何图像,因为有开源的预训练模型,所以我们也可以在自己的机器上运行它。
问题二:Stable Diffusion和novelAI有什么差异?
Stable Diffusion 的训练数据集是 LAION-5B,这个数据库拥有从互联网上抓取的 58 亿「图像-文本」数据;NovelAI 训练数据大量来自 Danbooru,"Danbooru"是一个图片搜索和分享网站,它主要提供了许多来自日本动画、漫画和游戏的图片,NovelAI 就是用 Danbooru 的图片在 Stable Diffusion 的基础上做了模型的优化训练(fine-tune)
简而言之,NovelAI 几乎只能生成动漫、手绘、素描、CG 风格的图片,但在这些风格的人像上出图率更高,是专精型选手;Stable Diffusion 相比之下不擅长生成动漫图片,但对于摄影、油画、水彩、概念艺术等风格都能全面掌握,更像一个全能选手。
问题三:如何使用Stable Diffusion?
Windows系统下载安装StableDiffusion,具体教程请Google。
问题四:Stable Diffusion对硬件配置有要求吗?
对硬件要求挺高,基本要3系以上显卡,显存至少要8GB
SD的模型占据的硬盘也比较多,至少有20-30GB空间。
问题五:硬件达不到要求,如何使用?
a.可以选择租用算力云服务器,很便宜,而且是按需计费,比如Ucloud,或者autoDL。
b.可以使用谷歌的colab来部署Stable Diffusion进行绘图。
问题六:Stable Diffusion收费吗?
Stable Diffusion免费,单独安装部署在自己的机器运行即可
问题七:Stable Diffusion都有哪些模型?
模型非常多,建议可以前往civitAI去搜索自己想要的模型
问题八:如何用Stable Diffusion做美女小姐姐?
一般会使用lora+chillmixout+koreandolllikeness 三合一模型出图。